






什么是RDD
RDD(弹性分布式数据集)是Apache Spark的核心抽象之一。它是一个不可变的、可分区的数据集合,可以分布在多个节点上。RDD提供了丰富的操作接口,包括转换(transformation)和行动(action),使得对大规模数据集的处理变得高效且易于编程。
RDD计算的高效性
RDD的高效性主要体现在以下几个方面:
弹性
RDD能够在节点失败时自动恢复。当某个节点上的数据因为故障而丢失时,RDD的分区可以从其他节点上的副本中重建,保证了数据的完整性和系统的稳定性。
并行计算
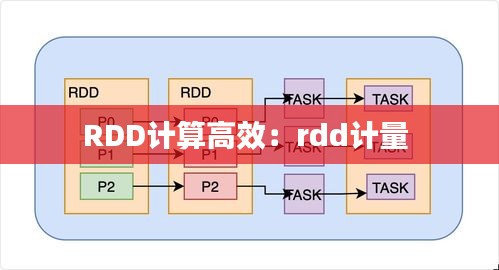
RDD支持并行计算,它可以将数据分片,并在多个节点上并行处理。这种并行处理能力使得Spark能够高效地处理大规模数据集。
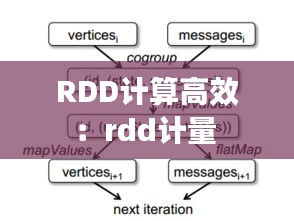
容错性
由于RDD的不可变性,每次操作都会生成一个新的RDD,这样即使某个操作失败,也不会影响到原始数据。这种设计使得Spark具有很高的容错性。
高效的数据访问
RDD支持多种数据源,如HDFS、HBase、Cassandra等。它通过将数据存储在分布式文件系统上,实现了高效的数据访问。此外,RDD的分区机制也使得数据的读取和写入更加高效。
RDD转换与行动操作
RDD提供了丰富的转换和行动操作,这些操作使得对数据的处理更加灵活和高效。
转换操作
转换操作是指对RDD进行一系列变换,生成新的RDD。例如,map、filter、flatMap、groupBy等。这些操作在执行时不会立即计算结果,而是返回一个新的RDD,直到执行行动操作时才会计算。

行动操作
行动操作是指触发RDD计算的操作,如count、collect、reduce、take等。这些操作会触发RDD的转换操作,并返回一个结果或执行一些副作用。
RDD的内存管理
RDD的内存管理是其高效性的关键之一。Spark利用了内存的局部性原理,将数据存储在内存中,从而提高了数据访问速度。当内存不足时,Spark会自动将数据溢写到磁盘,以保证程序的正常运行。
持久化与缓存
Spark提供了持久化和缓存机制,可以将RDD存储在内存或磁盘上,以便重复使用。这大大减少了重复计算的开销,提高了程序的效率。
总结
RDD计算的高效性源于其弹性、并行计算、容错性、高效的数据访问以及丰富的操作接口。通过RDD,Spark能够高效地处理大规模数据集,成为了大数据处理领域的首选框架。
随着大数据时代的到来,RDD计算的高效性将越来越受到重视。未来,随着技术的不断发展,RDD的计算效率将进一步提升,为大数据处理带来更多可能性。
转载请注明来自东营众达包装有限责任公司,本文标题:《RDD计算高效:rdd计量 》






 鲁ICP备2020041603号-1
鲁ICP备2020041603号-1
还没有评论,来说两句吧...